大语言模型[119]
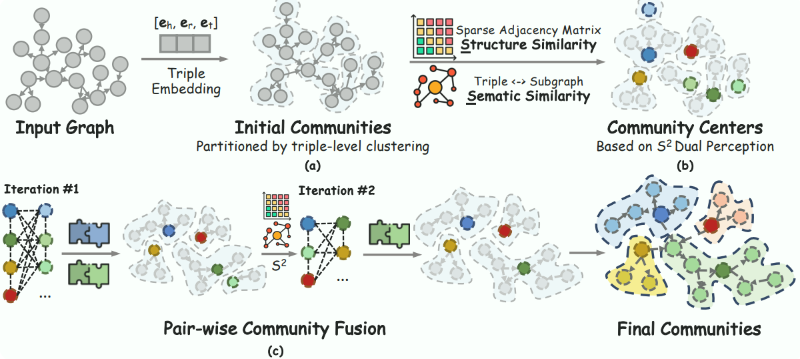
腾讯优图开源Youtu-GraphRAG:图检索增强技术实现成本与效果双突破
GraphRAG是大模型处理复杂领域知识的核心技术,却面临成本高、推理弱、适配难痛点。腾讯优图开源Youtu-GraphRAG框架,通过Schema引导等三大技术创新,实现知识图谱构建成本降30%+、复杂推理准确率升16%+,跨领域适配成本降60%+,支持医疗多跳推理、企业知识库管理等场景,已开源助力多行业落地。

Google发布VaultGemma:10亿参数开源差分隐私大模型开启AI隐私保护新纪元
2025年9月,Google发布全球首个10亿参数开源差分隐私大模型VaultGemma,通过“DP缩放定律”突破隐私-性能权衡难题,开放完整权重(Hugging Face/Kaggle可下载),为医疗、金融等隐私敏感场景提供实用技术范式,重新定义隐私保护大模型标准。
Transformer发明者Vaswani:闭源AI阻碍创新,Essential AI力推西方版DeepSeek
Transformer之父Ashish Vaswani带领Essential AI从商业项目转向开源基础AI研究,破解行业闭源困境。对标中国DeepSeek,以MoE架构推动“高性能+低成本”模型研发,通过“交叉补贴”模式保障开源可持续,助力AI从技术垄断走向科学共享,加速实现AI普惠。
百度ERNIE-4.5-21B-A3B-Thinking登顶HuggingFace文本模型趋势榜
百度ERNIE-4.5-21B-A3B-Thinking登顶HuggingFace全球文本模型趋势榜,总榜位列第三,中国AI技术再获国际认可。该模型采用MoE架构与稀疏激活设计,210亿总参数仅激活30亿,实现轻量高性能。支持128K长上下文(约25万字)及高效工具调用,开源降低应用门槛,推动金融、医疗等复杂场景落地。
蚂蚁集团与人大联合发布业界首个原生MoE架构扩散语言模型LLaDA-MoE 即将开源
蚂蚁集团与人大联合研发业界首个原生MoE架构dLLM——LLaDA-MoE。该模型基于20TB数据训练,性能比肩主流自回归模型,推理速度有数倍优势,即将完全开源。其融合动态路由与扩散机制,在代码生成、数学推理等任务表现突出,为AI领域提供新研究方向与高效解决方案。
字节跳动发布AgentGym-RL:多轮智能体强化学习框架,摒弃监督微调性能超商业模型
字节跳动推出业界首个统一多轮智能体强化学习框架AgentGym,采用纯强化学习路径,无需监督微调,智能体通过与环境交互自主掌握多样化任务。框架含AgentEvo环境集合及模块化设计,覆盖网页交互、游戏策略、具身智能、科学数据分析等27项任务,多项核心指标超越主流商业模型。
vLLM与Thinking Machines组建新研发团队 加速开源推理引擎生态建设与大模型服务能力提升
vLLM作为开源推理引擎明星,凭借PagedAttention技术突破LLM推理效率瓶颈。近日核心开发者Woosuk Kwon携手Thinking Machines组建新团队,聚焦Blackwell GPU适配、分布式推理优化及万亿参数模型支持,加速开源生态建设,助力企业低成本部署大模型,推动AI应用落地“最后一公里”。
NVIDIA发布SATLUTION:LLM自主进化SAT求解器
布尔可满足性问题(SAT)作为NP完全问题,是芯片验证、漏洞检测等领域的技术基石。传统SAT求解器依赖专家手工优化,面临代码复杂、迭代低效瓶颈。NVIDIA推出SATLUTION框架,以LLM驱动完整代码库进化,通过AI自主迭代与分布式验证,在国际竞赛中超越人类冠军方案,多场景性能领先,开启AI重塑复杂系统开发新范式。
Backprompting技术革新LLM健康建议防护栏:小模型准确率超GPT-4o
LLM健康建议安全需防护栏保障,数据稀缺成技术落地瓶颈。IBM提出Backprompting技术,通过四步流程生成合成不良数据,破解数据难题。其训练的1000万参数小模型健康建议识别准确率超GPT-4o,推动医疗等垂直领域AI安全防护普及,为AI安全提供新范式。
谷歌AI新突破:融合LLM与树搜索,自动生成专家级科研软件性能超越人类
谷歌AI团队2025年9月发布里程碑成果:科研软件自动生成系统,通过LLM与树搜索算法深度结合,实现多源知识整合与代码迭代创新。该系统在基因组学(单细胞RNA测序性能提升14%)、地理空间分析(卫星图像分割IoU超0.80)、神经科学(模型训练提速数级)等多领域突破,推动AI从自动化工具升级为科研创新“思想引擎”。